تدوین: رامین کریمی
www.kharazmi-statistics.ir
برآورد حجم نمونه
با فرمول کوکران و جدول مورگان
هدف محقق، شناسایی جامعه و تعیین پارامترهای مربوط به آن است و برای این کار یا باید به کلیه افراد جامعه مراجعه کند و صفت یا ویژگی مورد نظر تحقیق خود را در آن ها جویا شود یا باید تعدادی از افراد جامعه را مورد مطالعه قرار دهد و از طریق جمع کوچک تری و با روش معینی، پی به صفات و ویژگی های جامعه ببرد. بدیهی است اگر جامعه مورد نظر کوچک و حجم و تعداد افراد آن کم باشد، می تواند آن را به طور کامل مطالعه نماید ولی اگر جامعه بزرگ باشد و امکانانات و مقدورات وی اجازه ندهد، ناچار است از بین افراد جامعه تعداد مشخصی را به عنوان نمونه برگزیند و با مطالعه این جمع محدود، ویژگی ها و صفات جامعه را مطالعه کرده، شاخص ها و اندازه های آماری آن را محاسبه کند. از آنجا که جوامع آماری معمولاً از حجم و وسعت جغرافیایی زیادی برخوردارند و محققان نمی تواند به تمام آن ها مراجعه کنند، بنابراین ناگزیرند به انتخاب جمعی از آن ها به عنوان نمونه و تعمیم نتایج آن به جامعه مورد مطالعه اکتفا کند، در اینجاست که محقق راه نمونه گیری را انتخاب می کند(حافظ نیا، 144:1389).
سوالی که در جریان تحقیق پیش می آید این است که محقق چه تعداد از افراد جامعه مورد مطالعه را می تواند به عنوان نمونه تعیین کند یا به عبارتی حجم و تعداد افراد نمونه چند نفر باید باشد تا محقق بتواند با اطمینان خاطر نتایج حاصل و شاخص های محاسبه شده را به جامعه مورد مطالعه تعمیم دهد. یکی از روش های برآورد حجم نمونه استفاده از تکنیک ها و روش های آماری است. استفاده از این روش ها نیازمند دانستن اطلاعاتی در مورد جامعه ای که قصد انتخاب نمونه از آن را داریم است. از روش های مورد استفاده برای برآورد حجم نمونه، استفاده از فرمول کوکران و جدول کرجسی و مورگان است.
الف) فرمول کوکران
از این فرمول برای برآورد حجم نمونه در متغیرهای کیفی استفاده می شود. فرمول کوکران (Cochran) و اجزای آن در ادامه آورده شده است.
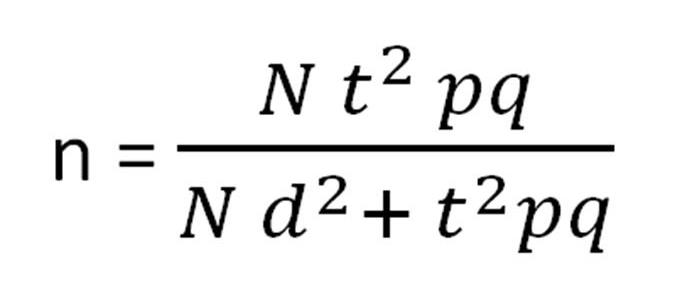
N = تعداد کل جمعیت آماری
t= ضریب اطمینان، که چنانچه سطح معنی داری آزمون برابر با 05/. باشد، مقدار این ضریب برابر است با1.96
p= احتمال وجود صفت در جامعه(نسبت جمعیت دارای صفت معین)
q=احتمال عدم وجود صفت در جامعه (نسبت جمعیت فاقد صفت معین) =1-p
d= دقت نمونه گیری (تفاضل نسبت واقعی صفت در جامعه با میزان تخمین محقق برای وجود آن صفت در جامعه)
برای برآورد حجم نمونه در متغیرهای کمّی از فرمول زیر استفاده می شود. تنها تفاوت این فرمول با فرمول بالا در این است که به جای نسبت pqاز 2sاستفاده می شود که واریانس صفت در جامعه است. به بیان دیگر چنانچه متغیر از نوع کمی باشد و واریانس صفت مدنظر در جامعه معلوم باشد از این فرمول استفاده می کنیم.
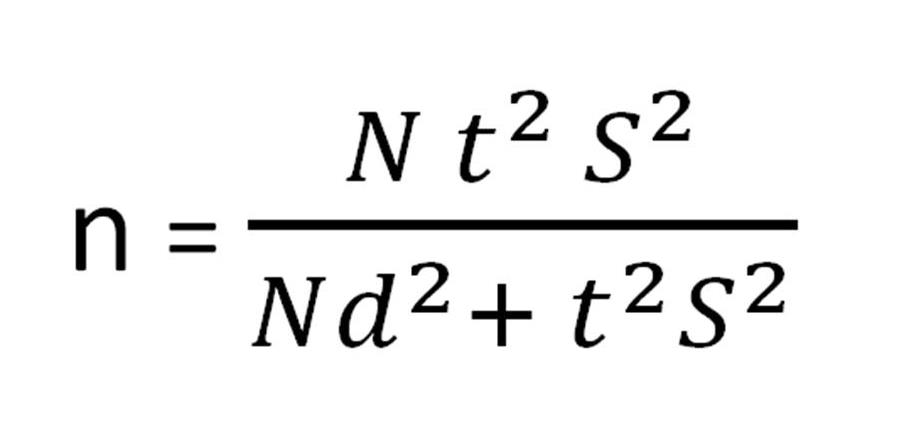
مثال
قصد داریم میزان رضایت سیاسی شهروندان شهر تهران را بدست بیاوریم.از آنجا که اطلاعات مورد اعتماد در زمینه برای برآورد واریانس وجود نداشت ناچار شدیم که مقدار pو qرا 5/. در نظر می گیریم و همانطور که می دانیم در این حالت بالاترین حجم نمونه بدست می آید. pبه معنای افرادی است که رضایت سیاسی دارند و qبه معنای افرادی است که رضایت سیاسی ندارند.
با استفاده از فرمول کوکران حجم نمونه برابر است با:
N یا جمعیت شهر تهران(بنا بر سرشماری سال 90) = 8293140
t یا ضریب اطمینان 95% = 1.96
pو qیا میزان همگنی جمعیت(در محافظه کارترین حالت) =5/.
dیا دقت نمونه گیری = 5%
که با جای گذاری مقادیر بالا حجم نمونه بدست می آید که برابر است با 384 نفر.
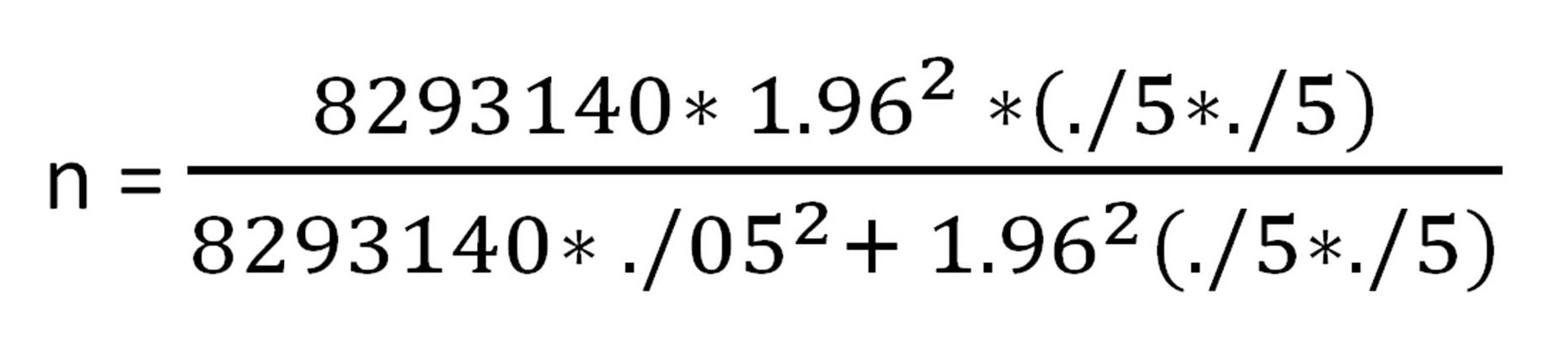
ب) جدول کرجسی و مورگان
همچنین می توان از جدول کرجسی و مورگان (Krejcie and Morgan)برای برآورد حجم نمونه استفاده کرد که این روش، روش ساده تری در مقایسه با فرمول های تخمین حجم نمونه است. در جدول کرجسی و مورگان با اطلاع از حجم جمعیت، می توانیم حجم نمونه مناسب را برآورد کنیم. جدول کرجسی و مورگان ارائه شده، حداکثر نمونه مورد نیاز را بدست می دهد.
|
حجم جمعیت |
حجم نمونه |
حجم جمعیت |
حجم نمونه |
حجم جمعیت |
حجم نمونه |
حجم جمعیت |
حجم نمونه |
حجم جمعیت |
حجم نمونه |
|
10 |
10 |
100 |
80 |
280 |
162 |
800 |
260 |
2800 |
338 |
|
15 |
14 |
110 |
86 |
290 |
165 |
850 |
265 |
3000 |
341 |
|
20 |
19 |
120 |
92 |
300 |
169 |
900 |
269 |
3500 |
246 |
|
25 |
24 |
130 |
97 |
320 |
175 |
950 |
274 |
4000 |
351 |
|
30 |
28 |
140 |
103 |
340 |
181 |
1000 |
278 |
4500 |
351 |
|
35 |
32 |
150 |
108 |
360 |
186 |
1100 |
285 |
5000 |
357 |
|
40 |
36 |
160 |
113 |
380 |
181 |
1200 |
291 |
6000 |
361 |
|
45 |
40 |
180 |
118 |
400 |
196 |
1300 |
297 |
7000 |
364 |
|
50 |
44 |
190 |
123 |
420 |
201 |
1400 |
302 |
8000 |
367 |
|
55 |
48 |
200 |
127 |
440 |
205 |
1500 |
306 |
9000 |
368 |
|
60 |
52 |
210 |
132 |
460 |
210 |
1600 |
310 |
10000 |
373 |
|
65 |
56 |
220 |
136 |
480 |
214 |
1700 |
313 |
15000 |
375 |
|
70 |
59 |
230 |
140 |
500 |
217 |
1800 |
317 |
20000 |
377 |
|
75 |
63 |
240 |
144 |
550 |
225 |
1900 |
320 |
30000 |
379 |
|
80 |
66 |
250 |
148 |
600 |
234 |
2000 |
322 |
40000 |
380 |
|
85 |
70 |
260 |
152 |
650 |
242 |
2200 |
327 |
50000 |
381 |
|
90 |
73 |
270 |
155 |
700 |
248 |
2400 |
331 |
75000 |
382 |
|
95 |
76 |
270 |
159 |
750 |
256 |
2600 |
335 |
100000 |
384 |
نکته: چنانچه حجم جمعیت از 100 هزار نفر تا 300 میلیون نفر باشد، حجم نمونه بر اساس جدول مورگان برابر با 384 نفر است.
نکته: حجم نمونه در سطح اطمینان 95 درصد محاسبه شده است.
نکته: دقت نمونه گیری یا حاشیه خطا (d) برابر با 5 درصد فرض شده است.
منابع:
حافظ نیا، محمدرضا (1389) مقدمه ای بر روش تحقیق در علوم انسانی، تهران: انتشارات سمت.
تدوین: رامین کریمی
www.kharazmi-statistics.ir